💸 Spend Tracking
Track spend for keys, users, and teams across 100+ LLMs.
How to Track Spend with LiteLLM
Step 1
👉 Setup LiteLLM with a Database
Step2 Send /chat/completions request
- OpenAI Python v1.0.0+
- Curl Request
- Langchain
import openai
client = openai.OpenAI(
api_key="sk-1234",
base_url="http://0.0.0.0:4000"
)
response = client.chat.completions.create(
model="llama3",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
user="palantir",
extra_body={
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}
)
print(response)
Pass metadata as part of the request body
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"user": "palantir",
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}'
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
import os
os.environ["OPENAI_API_KEY"] = "sk-1234"
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "llama3",
user="palantir",
extra_body={
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
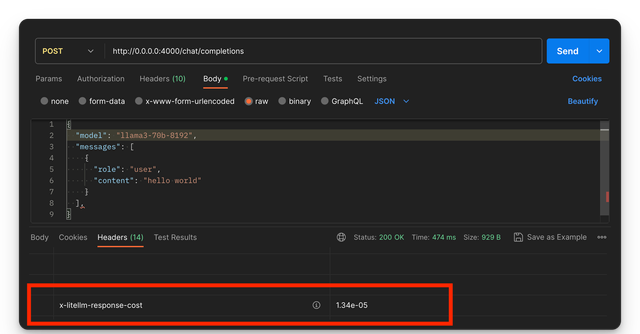
Step3 - Verify Spend Tracked That's IT. Now Verify your spend was tracked
- Response Headers
- DB + UI
Expect to see x-litellm-response-cost in the response headers with calculated cost
The following spend gets tracked in Table LiteLLM_SpendLogs
{
"api_key": "fe6b0cab4ff5a5a8df823196cc8a450*****", # Hash of API Key used
"user": "default_user", # Internal User (LiteLLM_UserTable) that owns `api_key=sk-1234`.
"team_id": "e8d1460f-846c-45d7-9b43-55f3cc52ac32", # Team (LiteLLM_TeamTable) that owns `api_key=sk-1234`
"request_tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"],# Tags sent in request
"end_user": "palantir", # Customer - the `user` sent in the request
"model_group": "llama3", # "model" passed to LiteLLM
"api_base": "https://api.groq.com/openai/v1/", # "api_base" of model used by LiteLLM
"spend": 0.000002, # Spend in $
"total_tokens": 100,
"completion_tokens": 80,
"prompt_tokens": 20,
}
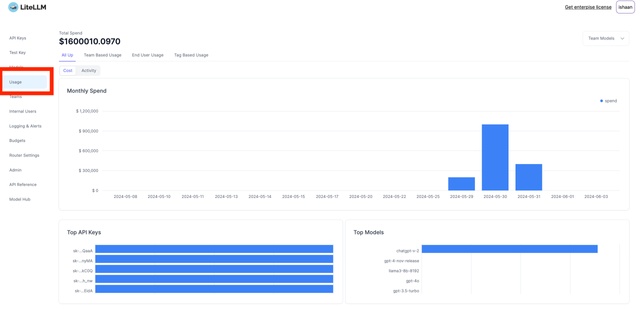
Navigate to the Usage Tab on the LiteLLM UI (found on https://your-proxy-endpoint/ui) and verify you see spend tracked under Usage
✨ (Enterprise) API Endpoints to get Spend
Getting Spend Reports - To Charge Other Teams, Customers, Users
Use the /global/spend/report endpoint to get spend reports
- Spend Per Team
- Spend Per Customer
- Spend for Specific API Key
- Spend for Internal User (Key Owner)
Example Request
👉 Key Change: Specify group_by=team
curl -X GET 'http://localhost:4000/global/spend/report?start_date=2024-04-01&end_date=2024-06-30&group_by=team' \
-H 'Authorization: Bearer sk-1234'
Example Response
- Expected Response
- Script to Parse Response (Python)
[
{
"group_by_day": "2024-04-30T00:00:00+00:00",
"teams": [
{
"team_name": "Prod Team",
"total_spend": 0.0015265,
"metadata": [ # see the spend by unique(key + model)
{
"model": "gpt-4",
"spend": 0.00123,
"total_tokens": 28,
"api_key": "88dc28.." # the hashed api key
},
{
"model": "gpt-4",
"spend": 0.00123,
"total_tokens": 28,
"api_key": "a73dc2.." # the hashed api key
},
{
"model": "chatgpt-v-2",
"spend": 0.000214,
"total_tokens": 122,
"api_key": "898c28.." # the hashed api key
},
{
"model": "gpt-3.5-turbo",
"spend": 0.0000825,
"total_tokens": 85,
"api_key": "84dc28.." # the hashed api key
}
]
}
]
}
]
import requests
url = 'http://localhost:4000/global/spend/report'
params = {
'start_date': '2023-04-01',
'end_date': '2024-06-30'
}
headers = {
'Authorization': 'Bearer sk-1234'
}
# Make the GET request
response = requests.get(url, headers=headers, params=params)
spend_report = response.json()
for row in spend_report:
date = row["group_by_day"]
teams = row["teams"]
for team in teams:
team_name = team["team_name"]
total_spend = team["total_spend"]
metadata = team["metadata"]
print(f"Date: {date}")
print(f"Team: {team_name}")
print(f"Total Spend: {total_spend}")
print("Metadata: ", metadata)
print()
Output from script
# Date: 2024-05-11T00:00:00+00:00
# Team: local_test_team
# Total Spend: 0.003675099999999999
# Metadata: [{'model': 'gpt-3.5-turbo', 'spend': 0.003675099999999999, 'api_key': 'b94d5e0bc3a71a573917fe1335dc0c14728c7016337451af9714924ff3a729db', 'total_tokens': 3105}]
# Date: 2024-05-13T00:00:00+00:00
# Team: Unassigned Team
# Total Spend: 3.4e-05
# Metadata: [{'model': 'gpt-3.5-turbo', 'spend': 3.4e-05, 'api_key': '9569d13c9777dba68096dea49b0b03e0aaf4d2b65d4030eda9e8a2733c3cd6e0', 'total_tokens': 50}]
# Date: 2024-05-13T00:00:00+00:00
# Team: central
# Total Spend: 0.000684
# Metadata: [{'model': 'gpt-3.5-turbo', 'spend': 0.000684, 'api_key': '0323facdf3af551594017b9ef162434a9b9a8ca1bbd9ccbd9d6ce173b1015605', 'total_tokens': 498}]
# Date: 2024-05-13T00:00:00+00:00
# Team: local_test_team
# Total Spend: 0.0005715000000000001
# Metadata: [{'model': 'gpt-3.5-turbo', 'spend': 0.0005715000000000001, 'api_key': 'b94d5e0bc3a71a573917fe1335dc0c14728c7016337451af9714924ff3a729db', 'total_tokens': 423}]
Customer This is the value of user_id passed when calling /key/generate
Example Request
👉 Key Change: Specify group_by=customer
curl -X GET 'http://localhost:4000/global/spend/report?start_date=2024-04-01&end_date=2024-06-30&group_by=customer' \
-H 'Authorization: Bearer sk-1234'
Example Response
[
{
"group_by_day": "2024-04-30T00:00:00+00:00",
"customers": [
{
"customer": "palantir",
"total_spend": 0.0015265,
"metadata": [ # see the spend by unique(key + model)
{
"model": "gpt-4",
"spend": 0.00123,
"total_tokens": 28,
"api_key": "88dc28.." # the hashed api key
},
{
"model": "gpt-4",
"spend": 0.00123,
"total_tokens": 28,
"api_key": "a73dc2.." # the hashed api key
},
{
"model": "chatgpt-v-2",
"spend": 0.000214,
"total_tokens": 122,
"api_key": "898c28.." # the hashed api key
},
{
"model": "gpt-3.5-turbo",
"spend": 0.0000825,
"total_tokens": 85,
"api_key": "84dc28.." # the hashed api key
}
]
}
]
}
]
👉 Key Change: Specify api_key=sk-1234
curl -X GET 'http://localhost:4000/global/spend/report?start_date=2024-04-01&end_date=2024-06-30&api_key=sk-1234' \
-H 'Authorization: Bearer sk-1234'
Example Response
[
{
"api_key": "88dc28d0f030c55ed4ab77ed8faf098196cb1c05df778539800c9f1243fe6b4b",
"total_cost": 0.3201286305151999,
"total_input_tokens": 36.0,
"total_output_tokens": 1593.0,
"model_details": [
{
"model": "dall-e-3",
"total_cost": 0.31999939051519993,
"total_input_tokens": 0,
"total_output_tokens": 0
},
{
"model": "llama3-8b-8192",
"total_cost": 0.00012924,
"total_input_tokens": 36,
"total_output_tokens": 1593
}
]
}
]
Internal User (Key Owner): This is the value of user_id passed when calling /key/generate
👉 Key Change: Specify internal_user_id=ishaan
curl -X GET 'http://localhost:4000/global/spend/report?start_date=2024-04-01&end_date=2024-12-30&internal_user_id=ishaan' \
-H 'Authorization: Bearer sk-1234'
Example Response
[
{
"api_key": "88dc28d0f030c55ed4ab77ed8faf098196cb1c05df778539800c9f1243fe6b4b",
"total_cost": 0.00013132,
"total_input_tokens": 105.0,
"total_output_tokens": 872.0,
"model_details": [
{
"model": "gpt-3.5-turbo-instruct",
"total_cost": 5.85e-05,
"total_input_tokens": 15,
"total_output_tokens": 18
},
{
"model": "llama3-8b-8192",
"total_cost": 7.282000000000001e-05,
"total_input_tokens": 90,
"total_output_tokens": 854
}
]
},
{
"api_key": "151e85e46ab8c9c7fad090793e3fe87940213f6ae665b543ca633b0b85ba6dc6",
"total_cost": 5.2699999999999993e-05,
"total_input_tokens": 26.0,
"total_output_tokens": 27.0,
"model_details": [
{
"model": "gpt-3.5-turbo",
"total_cost": 5.2499999999999995e-05,
"total_input_tokens": 24,
"total_output_tokens": 27
},
{
"model": "text-embedding-ada-002",
"total_cost": 2e-07,
"total_input_tokens": 2,
"total_output_tokens": 0
}
]
},
{
"api_key": "60cb83a2dcbf13531bd27a25f83546ecdb25a1a6deebe62d007999dc00e1e32a",
"total_cost": 9.42e-06,
"total_input_tokens": 30.0,
"total_output_tokens": 99.0,
"model_details": [
{
"model": "llama3-8b-8192",
"total_cost": 9.42e-06,
"total_input_tokens": 30,
"total_output_tokens": 99
}
]
}
]
Allowing Non-Proxy Admins to access /spend endpoints
Use this when you want non-proxy admins to access /spend endpoints
Create Key
Create Key with with permissions={"get_spend_routes": true}
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"permissions": {"get_spend_routes": true}
}'
Use generated key on /spend endpoints
Access spend Routes with newly generate keys
curl -X GET 'http://localhost:4000/global/spend/report?start_date=2024-04-01&end_date=2024-06-30' \
-H 'Authorization: Bearer sk-H16BKvrSNConSsBYLGc_7A'
Reset Team, API Key Spend - MASTER KEY ONLY
Use /global/spend/reset if you want to:
Reset the Spend for all API Keys, Teams. The
spendfor ALL Teams and Keys inLiteLLM_TeamTableandLiteLLM_VerificationTokenwill be set tospend=0LiteLLM will maintain all the logs in
LiteLLMSpendLogsfor Auditing Purposes
Request
Only the LITELLM_MASTER_KEY you set can access this route
curl -X POST \
'http://localhost:4000/global/spend/reset' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json'
Expected Responses
{"message":"Spend for all API Keys and Teams reset successfully","status":"success"}
Spend Tracking for Azure OpenAI Models
Set base model for cost tracking azure image-gen call
Image Generation
model_list:
- model_name: dall-e-3
litellm_params:
model: azure/dall-e-3-test
api_version: 2023-06-01-preview
api_base: https://openai-gpt-4-test-v-1.openai.azure.com/
api_key: os.environ/AZURE_API_KEY
base_model: dall-e-3 # 👈 set dall-e-3 as base model
model_info:
mode: image_generation
Chat Completions / Embeddings
Problem: Azure returns gpt-4 in the response when azure/gpt-4-1106-preview is used. This leads to inaccurate cost tracking
Solution ✅ : Set base_model on your config so litellm uses the correct model for calculating azure cost
Get the base model name from here
Example config with base_model
model_list:
- model_name: azure-gpt-3.5
litellm_params:
model: azure/chatgpt-v-2
api_base: os.environ/AZURE_API_BASE
api_key: os.environ/AZURE_API_KEY
api_version: "2023-07-01-preview"
model_info:
base_model: azure/gpt-4-1106-preview
Custom Input/Output Pricing
👉 Head to Custom Input/Output Pricing to setup custom pricing or your models
✨ Custom k,v pairs
Log specific key,value pairs as part of the metadata for a spend log
Logging specific key,value pairs in spend logs metadata is an enterprise feature. See here
✨ Custom Tags
Tracking spend with Custom tags is an enterprise feature. See here